About Bfsync
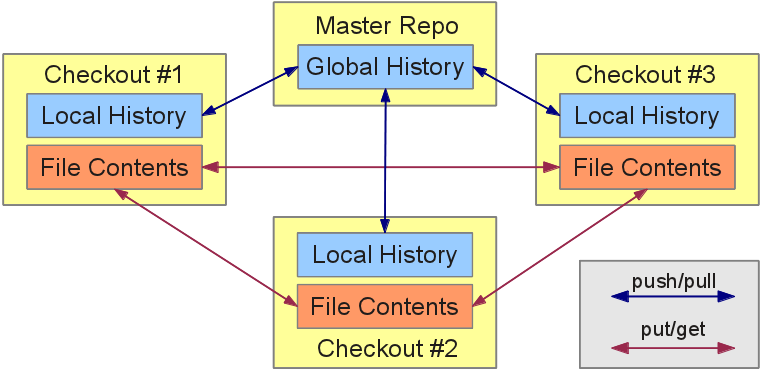
Bfsync is a file-synchronization tool which allows to keep a collection of big files synchronized on many machines. To do this, bfsync maintains a global and local history of changes; every time the file collection is changed on one machine, an entry in the local history is made. Bfsync allows to automatically merge this local history with the global history where possible, and offers manual conflict resolution in cases where this is not possible.
Due to history synchronization, each bfsync checkout knows precisely which files are part of the file collection. Therefore, it can determine which file contents (data blobs with SHA1 contents) are present in a checked out repo, and which are missing. The user can transfer file contents between repos using bfsync get/put, so that after transfer, the checkouts will be complete (containing both: the history and the file contents required).
To sum it up, bfsync behaves not unlike version control systems like git or svn, however it behaves reasonable when the file collection is big (like houndreds of gigabytes).
The main interface to bfsync is a FuSE filesystem, so it is possible to manage your data with a file manager or copy new data into the repository using rsync. As soon as you "commit" the changes, they are entered into the local history and if you "push/pull" the changes, they become part of the global history. There is no need to transfer all new data to a central server during "push/pull". Only the history needs to be transferred, the contents of the files can be exchanged between different machines without need for a central server (although you can have a central server containing all data if its practical for you).
Bfsync is implemented in C++ and Python and licensed under the GNU GPL version 3.
Bfsync & Backup
Bfsync was designed from the start to store all information a conventional filesystem would store. So it stores the user/group, permissions, symlinks, hardlinks, block devices, ... so it is possible to do a full system backup into a bfsync repository. By using rsync and then bfsync commit every day, a backup which automatically deduplicates at file level can be implemented. See the BACKUP WALKTHROUGH section of the bfsync manpage for details.
What Bfsync can do
- synchronize a collection of big files between many machines, where the collection is changed independently on different machines
- offline commits, so you can change files and commit on your laptop and resynchronize as soon as you have network connectivity again
- file-level deduplication, so storing a file twice under different names will not use more space than storing it once - also renames or removing a file and re-adding it will not retransfer the data, if the repository already has it
- storing all attributes, bfsync stores everything a normal filesystem would store, like user/group settings, permissions, symlinks, hard links, devices, ... (this is useful for backups)
- storing each file only once: many version control systems store files two times on the users machines, once internally and a second time as "checkout"; especially for huge files (mp3s, photos, videos) this is not convenient. bfsync stores each file only once, and provides a view on the data in the FuSE filesystem; it uses copy-on-write if a file is modified
- old versions remain available: bfsync keeps all files and all versions available in each checkout; within the filesystem there is a .bfsync/commits/N directory for all commits, so you can look at all old versions from within the filesystem
- rate-limiting: since big files take extremely long to transfer, bfsync allows to limit the bandwidth used for file transfer, so it can run in background without disturbing your normal work
- manage a huge number of files: since bfsync can be used for backups, the algorithms that are required for this use case have been optimized for speed and memory usage; other algorithms (like the merge algorithm) are not so optimized - if you have really lots of files (like 5.000.000 files), you can use bfsync to manage them, but some features like merging will not be usable
What Bfsync can't do
- branches, the history of bfsync is linear, so it can't do what advanced version control software like git can do
- textual merges, so bfsync will not be able to merge a text or source code file that has been independantly edited automatically - a rule of thumb is that if you need to merge a file in this way, you should use git (or another version control system) for the file; only put files into bfsync that will not require merging, like mp3s, videos, photos and similar
- partial checkouts (not yet), which means that you can exclude directories from being synchronized to a certain destination (for instance to avoid synchronizing the videos directory to your laptop) - this will probably be supported in one of the next releases
- automatic synchronization (not yet), currently there are commands that the user needs to use to synchronize the data, mostly bfsync commit/push/pull/get/put; other file synchronization software like "Dropbox" starts automatically synchronizing the data once its stored in the file collection directory; it should be possible to allow a similar interaction-free synchronization in some future release of Bfsync; however conflicts will still need to be handled somehow (what happens if I rename X to X1 on machine 1 and X to X2 on machine 2); currently Bfsync does this during pull
Getting bfsync
The current version of bfsync is bfsync-0.3.7, and can be downloaded here:
The git repository can be cloned like this:
git clone http://space.twc.de/public/git/bfsync.git
and browsed via gitweb.
Overview of Changes in bfsync-0.3.7
Building bfsync 0.3.7 on Ubuntu
The following packages are required (and need to be installed with apt-get install before building):
- build-essential
- python-dev
- libfuse-dev
- libglib2.0-dev
- libdb++-dev
- libboost-dev
- python-setuptools
- python-lzma
- swig
If you want to build bfsync from git, you also need:
- libtool
- automake
- autoconf-archive
Documentation (bfsync-0.3.7)
Issue tracker
If you have issues/bugs related to bfsync, you can use the
issue tracker on github.
Discussion group
There is a group on google groups you can join to discuss questions related to using bfsync and development topics.
Older versions
Older versions are